AI Hallucinations in Consulting: How Errors Reach Client Deliverables and How to Stop Them

Table of Contents
Key Takeaways
- AI hallucinations in consulting are increasingly a byproduct of modern research workflows
- The impact can be material, with errors leading to financial loss and reputational damage
- AI-related errors tend to follow consistent patterns often overlooked in review processes
- Traditional review mechanisms are not designed to detect AI-generated inaccuracies at scale
- The solution is not to limit AI use, but to reintroduce independent verification
Artificial intelligence is accelerating how consulting work gets done. Research that once required coordinated teams can now be produced in hours.
What is less visible is how this shift is affecting reliability. As AI becomes embedded in delivery workflows, errors that appear credible are increasingly making their way into client outputs, not because of carelessness but because the processes designed to catch them have not kept pace.
The Incident That Made the Problem Visible
In 2025, a major professional services firm delivered a report to a government client that appeared, at first glance, entirely credible. The document was well structured, professionally written, and supported by what seemed to be legitimate citations and legal references. Only after closer scrutiny did it become clear that several of those references did not exist. The report included fabricated court quotes and invented sources that had been introduced during the AI-assisted research process and had passed through every internal review stage without being identified. The firm ultimately issued a partial refund of $290,000, while the reputational consequences of the incident were more difficult to measure but likely far more significant.
This case is often interpreted as a failure of artificial intelligence. In reality, it reflects a failure of process design. The AI system behaved as expected, producing output that was coherent, plausible, and authoritative in tone. The breakdown occurred in the mechanisms that were supposed to validate that output before it reached the client.
According to a McKinsey’s State of AI Survey published in November 2025, 88 percent reported using AI regularly in at least one business function compared to 78 percent the previous year. This means that AI-generated content is already embedded in a large share of professional workflows, including consulting delivery. As adoption continues to scale, the probability that AI-generated errors reach client-facing outputs increases accordingly.
Most consulting firms using AI in research workflows are now exposed to a similar risk. Across our engagements with leading advisory firms, a consistent pattern emerges. AI tools have been deployed, and the speed gains are real, but the independent validation layer that once ensured reliability has often been removed instead of being rebuilt.
Talk to our team about research verification for AI-assisted workflows →
How AI Compressed the One Process That Caught Errors
The core issue is not the presence of hallucinations, but the disappearance of the structure that historically prevented errors from reaching clients.
Before the adoption of AI, consulting research typically moved through a sequence of independent validation steps. Initial research, data enrichment and synthesis, and quality assurance were often handled by different individuals, each bringing a distinct perspective and a degree of separation from the original work. This separation ensured that errors introduced at one stage were likely to be identified at a later stage by someone with no cognitive investment in the initial output.
AI has fundamentally altered this model. Tasks that previously required multiple contributors can now be completed by a single consultant within hours. As a result, multiple research and analytical steps increasingly occur within a single workflow, with limited independent validation between steps.
The consequence is structural. Errors introduced early in the process are less likely to be challenged and can persist as they move through the workflow, becoming embedded within otherwise coherent analysis.
The Scale of the Problem Is Underestimated
The visibility of AI-related errors in consulting is inherently limited. While some issues are identified through review processes or client feedback, there is no systematic way to assess how consistently errors are detected across deliverables or where they may persist.
This limitation is particularly concerning given that reliability is already recognized as a core issue in AI adoption. McKinsey’s 2026 AI Trust Maturity Survey reports that inaccuracy is the most cited AI risk among respondents with direct responsibility for AI governance, risk management, or investment decisions. The challenge, therefore, is not awareness, but the ability to detect where these risks are already materializing in practice.
Consulting firms deploying AI in client-facing workflows operate under the same reliability constraints, but with materially higher stakes. Errors are no longer contained within internal analysis, they can be embedded in deliverables and influence client decisions. While some are identified through review processes, others may persist depending on the depth of validation applied.
The Four Ways AI Research Fails in Consulting
AI-generated errors follow recurring patterns that are structurally embedded in how LLMs generate output. Understanding these patterns is critical, because it allows firms to move from generic quality control to targeted verification.
1. Fabricated Citations
The first and most visible error is the fabrication of citations. LLMs are capable of producing references that appear entirely legitimate, combining plausible author names, journal titles, and publication dates into a coherent citation that does not actually exist. This can take the form of a reference to a seemingly credible source, such as a “2022 Harvard Business Review study by Smith and Rao on digital transformation outcomes” or a “World Bank report on emerging market infrastructure investment”, which reads as authoritative but cannot be retrieved or verified in any database or search engine.
In a consulting context, where the authority of a recommendation depends on the credibility of its underlying data, this creates a significant vulnerability. Scenario modeling, forecasts, market studies, and strategic frameworks are built on that data, meaning that a single incorrect input can distort the conclusions that follow. The issue extends beyond the initial error and affects the validity of the overall analysis. When challenged, and no underlying source can be identified to support the claim, the credibility of the deliverable erodes immediately.
2. Statistical Hallucinations
A second failure pattern involves the generation of precise but unsupported statistics. AI systems frequently produce specific numerical values that align with the narrative being developed, even when no verifiable source exists. This often takes the form of highly specific figures, such as a claim that “67 percent of firms report adopting a given capability” or that “the market reached $4.2 billion in 2025”, which appear credible because they match the expectations set by the analysis, but cannot be traced back to any underlying source.
These figures are particularly difficult to challenge during review because they appear consistent with the broader analysis. However, their impact can be disproportionate. A single invented statistic can shape a market sizing exercise, influence a growth projection, or reinforce a strategic recommendation. The authority conveyed by numerical precision often masks the absence of underlying evidence.
3. Plausible-but-Wrong Synthesis
A third and more subtle risk lies in what can be described as plausible but incorrect synthesis. In these cases, the individual data points and sources may be accurate, but the conclusion drawn from them is flawed. The model identifies patterns and relationships that are logically coherent but analytically incorrect. This often manifests in conclusions that appear reasonable at first glance. For example, inferring that a market is consolidating because a few large mergers have occurred, despite broader data showing increasing fragmentation, or concluding that a company’s growth is primarily driven by digital channels when the underlying data reflects a temporary shift rather than a structural trend.
This type of error is especially difficult to detect because it does not originate from a false input, but from a misinterpretation of correct information. Identifying it requires not just verification of sources, but independent re-analysis of the reasoning process itself.
4. Outdated Data Presented as Current
The final failure mode relates to the use of outdated information presented as current. Because LLMs rely on training data with defined cut-off points, they may present market figures, regulatory developments, competitive dynamics, or operating models and customer behavior that are no longer accurate. This can take the form of referencing pre-inflation cost assumptions in pricing analyses, relying on outdated supply chain configurations, or applying past consumer behavior patterns that no longer reflect current market conditions.
In fast-moving sectors, even a delay of a few months can materially affect the validity of an analysis. For example, a technology adoption rate that does not reflect recent acceleration can lead to conclusions that are directionally misleading. The risk is compounded by the fact that the information is presented with the same level of confidence as real-time data, making it difficult for reviewers to distinguish between current and outdated inputs without explicit verification.
Why Standard Review Processes Fail to Detect These Errors
The persistence of these systematic errors is not the result of insufficient diligence. It reflects a deeper misalignment between how consulting review processes are designed and how AI-generated content behaves.
The Reviewer Trusts the Research Layer
Traditional review frameworks assume that the research layer is fundamentally reliable. When a consultant submits a draft, the reviewer focuses primarily on the quality of the argument, the clarity of the structure, and the coherence of the conclusions. The underlying assumption is that the data has been sourced correctly and that the references are valid. This assumption has historically been reasonable in a human-led research process, where sourcing required deliberate effort and verification.
With AI-generated content, that assumption no longer holds. The research layer itself becomes uncertain, but the review process has not always adapted to account for that uncertainty. As a result, reviewers continue to evaluate outputs as if the foundational data were trustworthy, even when it may not be.
Cognitive Bias Reinforces the Output
A second structural issue arises from cognitive bias. As consultants invest time and effort in prompting, refining, and shaping AI-generated output, the result increasingly feels validated through iteration. This creates a higher level of confidence in the content, even when the underlying data or logic has not been independently verified. As a result, the threshold for critically challenging the output is higher, allowing errors to persist as the work progresses.
Volume Outpaces Review Capacity
The third constraint is volume. AI significantly increases the amount of content that can be produced within a given timeframe. However, review capacity does not expand at the same rate. In practical terms, the senior reviewer who previously evaluated a 20-page research output may now be required to assess 60 pages from the same team within the same time window. Senior reviewers are therefore required to assess larger volumes of material under unchanged time constraints, reducing the likelihood that any individual error will be identified. As output increases, the effectiveness of traditional review mechanisms declines proportionally.
The Iceberg Problem: The Risks You Don’t See
The most visible AI-related incidents in consulting represent only a small fraction of the total risk. What firms observe — client escalations, disputes, or formal corrections — are only the small, visible portion of a much larger underlying issue. Beneath the surface lies a significantly larger volume of AI-related errors that do not become publicly visible: issues that are identified and corrected internally, resolved without escalation, or simply never formally reported.
This creates an iceberg dynamic. The incidents that surface are not representative of the total volume of errors, but only those that reach a level of visibility through escalation or dispute. A much larger share remains below the surface, not because it does not exist, but because it is handled quietly or never captured.
Recent findings from McKinsey & Company reinforce this dynamic. While the number of AI-related incidents reported by organizations has remained relatively stable since 2025, confidence in how those incidents are handled has declined. In practice, this suggests not that risks are decreasing, but that organizations are becoming less certain in their ability to detect, manage, and respond to them effectively.
What a Verification Layer Looks Like in Practice
Addressing this risk does not require reducing the use of AI. The efficiency gains are substantial, and AI is already reshaping how consulting work is delivered. The challenge is to adapt the process around it, restoring independent validation while preserving speed.
In practice, this means introducing a dedicated verification layer that operates independently from the initial AI-assisted research process and is designed to address how AI-generated errors occur.
Without this layer, errors introduced early in the workflow can persist as they move through synthesis, drafting, and review, becoming progressively harder to detect as they are embedded in increasingly complete and coherent outputs.
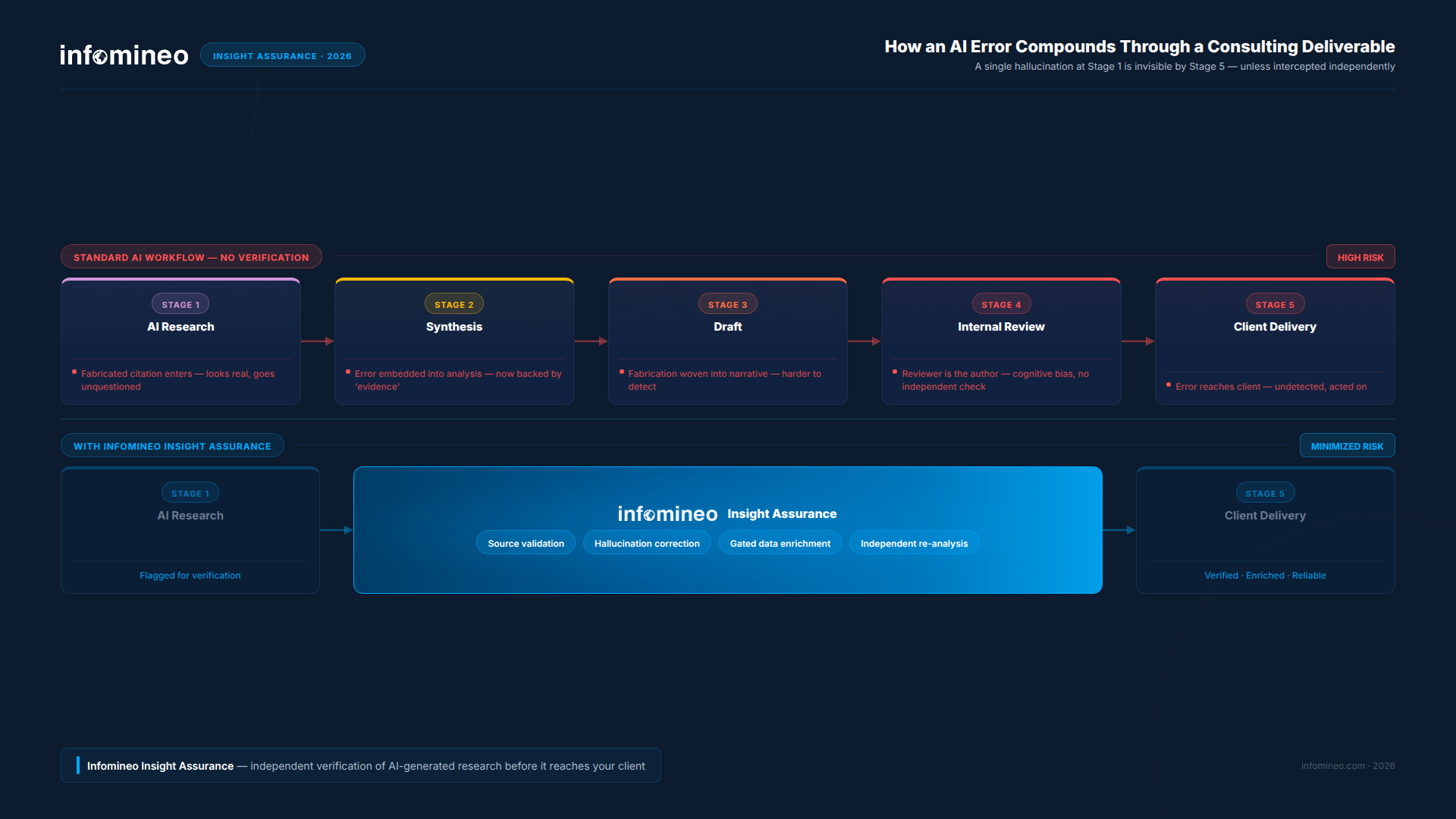
As shown, the issue is not the presence of errors at the initial stage, but the absence of mechanisms to intercept them as the workflow progresses. Each step reinforces the output rather than challenging it, allowing initial inaccuracies to carry forward into the final deliverable.
This dynamic reflects a shift in how research workflows operate. As independent validation steps are reduced, the process no longer systematically tests the underlying data and reasoning at each stage. Reintroducing that independence, without compromising the efficiency gains AI provides, becomes essential to ensure reliable outputs.
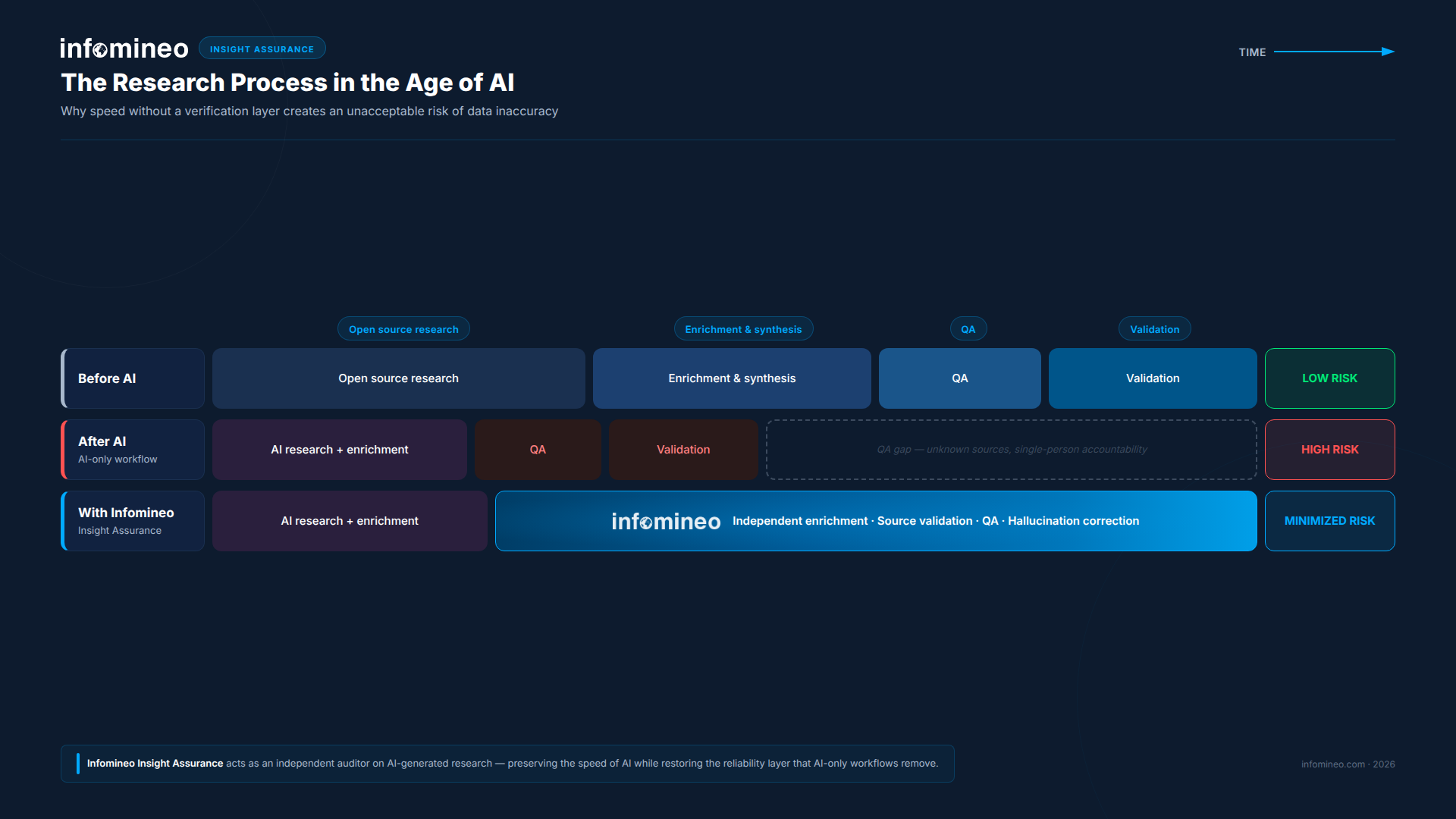
In practice, this approach is not a single step, but a set of complementary mechanisms designed to address how AI-generated errors occur across the workflow.
Independent Source Validation
The first component of this layer is independent source validation. Every citation in an AI-generated output must be traced back to its original source and verified, confirming both its existence and the accuracy of the cited data. This ensures that the analysis is grounded in reliable data and sound reasoning.
Enrichment with Gated and Primary Sources
A second element is the enrichment of AI-generated output with proprietary and primary data. AI systems operate mostly on publicly available information and do not have access to premium databases, internal knowledge, or primary research. As a result, their outputs often rely on widely available inputs or approximations. As AI adoption scales, this limitation becomes more pronounced. Firms using similar tools and datasets increasingly arrive at comparable baseline analyses, commoditizing the output of AI-assisted research.
Enriching this output with verified, non-public data serves two purposes. It improves the accuracy of the analysis and strengthens its evidentiary foundation, while also introducing a level of differentiation that cannot be replicated through standard AI use. For consulting firms, this becomes a critical source of value, particularly in an environment where clients expect not just speed, but defensible and differentiated perspectives.
Full Research Rework When Stakes Require It
Finally, there are cases where incremental correction is insufficient. For high-stakes deliverables, such as regulatory submissions, board-level strategy decisions, or transaction-related work, the risk associated with AI-generated errors may justify a full rework of the research rather than a targeted correction. This requires a clear decision framework that distinguishes between outputs that can be verified and those that must be rebuilt from the ground up.
Not all use cases carry the same level of risk, and as a result, they do not require the same level of validation. The appropriate depth of review must be calibrated to the context in which the output will be used and the consequences of error. The objective is not to eliminate risk entirely, but to align the level of validation with the potential impact of getting it wrong.
At Infomineo, this model is applied through the Insight Assurance model, combining independent validation, proprietary data enrichment, and AI-specific quality controls to restore reliability in AI-assisted workflows. To learn more about how this can be implemented in practice, or to assess your current exposure, speak directly with one of our team members!
The Commercial Implication for Getting it Right
The case for strengthening verification is not limited to risk mitigation. It is increasingly shaping how consulting firms defend their work in commercial discussions.
As AI becomes embedded in delivery, clients are paying closer attention not only to the quality of the output, but to how it was produced. The visibility of AI-driven efficiency is changing expectations around effort, transparency, and pricing.
This shift is already influencing negotiations. In one recent case, a Big Four firm imposed a 14 percent fee reduction on its long-time auditor, with AI-driven efficiency explicitly cited as justification. This is an early signal of a broader change in how work is evaluated.
In this context, the ability to demonstrate how analysis has been validated becomes commercially relevant. It provides a clearer basis for explaining the work performed, the robustness of the conclusions, and the difference between standard output and a deliverable that has been independently verified and strengthened.
The verification layer therefore serves not only as a control mechanism, but as part of how value is communicated. It supports a more defensible positioning in client discussions, particularly where expectations around efficiency and pricing are evolving, and increasingly forms part of broader AI governance frameworks that define how outputs are validated, controlled, and trusted.
INSIGHT ASSURANCE
Independent verification for AI-generated research…before it reaches your client.
Infomineo’s Insight Assurance operates as an independent audit layer for AI-generated consulting research. We validate sources, correct hallucinations, enrich outputs with gated data AI cannot access, and escalate to full rework when the deliverable demands it. Built for firms that want AI’s speed without accepting its error rate.
Frequently Asked Questions
What are AI hallucinations and why do they matter in consulting?
AI hallucinations refer to outputs generated by LLMs that appear credible but are factually incorrect, including fabricated citations, invented statistics, or conclusions not supported by evidence. In a consulting context, where the value of a deliverable depends on the accuracy and credibility of its research, these errors introduce material risk. When hallucinations reach the client, the consequences include financial exposure, reputational damage, and erosion of trust.
How do AI hallucinations get past consulting review processes?
AI hallucinations persist not because of a lack of diligence, but because consulting review processes were designed for human-generated research and rely on assumptions that no longer hold. Reviewers typically focus on the quality of the argument rather than verifying whether the underlying data is correct. At the same time, cognitive bias plays a role: consultants who invest time and effort in shaping AI-generated output are more likely to perceive it as reliable, reducing the likelihood that it is critically challenged. Combined with increasing content volumes and unchanged review capacity, these factors make errors less likely to be identified before reaching the client.
What types of AI errors are most common in consulting research?
AI errors in consulting tend to follow recurring patterns rather than occurring randomly. The most common include fabricated citations that appear legitimate but do not exist, precise numerical claims that lack a verifiable source, and analytical conclusions that are logically coherent but incorrect despite being based on real data. Another frequent issue is the use of outdated information presented as current, particularly in fast-moving sectors where even a short lag can materially affect the validity of an analysis. Each of these failure modes requires a different form of verification, as they stem from distinct limitations in how AI systems generate and synthesize information.
What is an AI verification layer in consulting?
An AI verification layer is a structured, independent process designed to validate AI-assisted research before it reaches the client. In practice, this involves systematically verifying sources and enriching analysis with proprietary or primary data that the model cannot access. Crucially, this process is performed independently from the initial research, restoring the separation that historically ensured reliability in consulting workflows and ensuring that AI-generated outputs meet the standards expected in client-facing work.
Is independent AI research verification worth the cost?
For most consulting engagements, the cost of an undetected AI error exceeds the cost of preventing it, as client challenges, financial adjustments, reputational impact, and lost future work can quickly outweigh the investment required for proper verification. Beyond risk mitigation, there is also a clear commercial dimension: as AI adoption increases, baseline analytical output is becoming more standardized, making independently verified and enriched research a key source of differentiation. The verification layer therefore serves both as a safeguard against risk and as a mechanism to sustain the value and pricing of consulting work in an increasingly AI-enabled market.